Du baust eine KI-Lösung, tauschst ein Modell, änderst einen Prompt, drehst an einem Parameter. Die Ausgabe sieht anders aus. Die Frage die sich niemand gerne stellt: Ist sie besser geworden, oder nur anders?
Wer darauf mit Bauchgefühl antwortet, baut im Dunkeln.
Warum Spot-Checking nicht reicht
KI-Systeme sind nicht deterministisch. Zwei Runs auf demselben Input liefern oft unterschiedliche Ergebnisse. Dazu kommt, dass du bei jeder Änderung nie nur einen Effekt hast. Ein neuer Prompt verbessert vielleicht drei Fälle und macht zwei andere schlechter. Wenn du dir nach der Änderung nur ein paar Beispiele anschaust, siehst du die Verbesserung und übersiehst die Regression.
Die saubere Antwort darauf heißt: fixer Referenzdatensatz, manuell verifizierte Ground Truth, und jeder neue Release wird gegen denselben Datensatz gemessen.
Das ist der Golden Set.
Das Konzept Golden Set
Ein Golden Set ist ein fixer Pool an Beispielen aus deinem echten Anwendungsfall, bei denen du die richtige Antwort kennst. Nicht synthetisch, nicht ausgedacht, nicht aus einem Benchmark. Echte Inputs aus deinem Produkt, manuell durchgetaggt.
Jeder neue Modell-Release, jede Prompt-Änderung, jeder neue Parameter-Wert wird gegen diesen Set laufen gelassen. Die Metriken sagen dir, ob die Änderung netto gut oder schlecht war.
Konkretes Beispiel: DropCut.ai
DropCut.ai ist meine Plattform für Mountainbike-Action-Videos. Der Kern ist eine Engine, die aus einem rohen Helmkamera-Clip automatisch die relevanten Segmente erkennt: Jumps, Drops, Tricks, Riding.
Solange ich nur ein Modell hatte, war die Qualität schwer zu greifen. Ich habe mir einen Clip angeschaut, das Ergebnis war ok oder nicht. Als ich angefangen habe, einzelne Detection-Bricks zu tauschen und Parameter zu drehen, wurde der Bedarf offensichtlich: Ich brauchte Messwerte, nicht Eindrücke.
Also habe ich mir eine eigene Evaluation-Engine inklusive Golden-Set Builder gebaut.
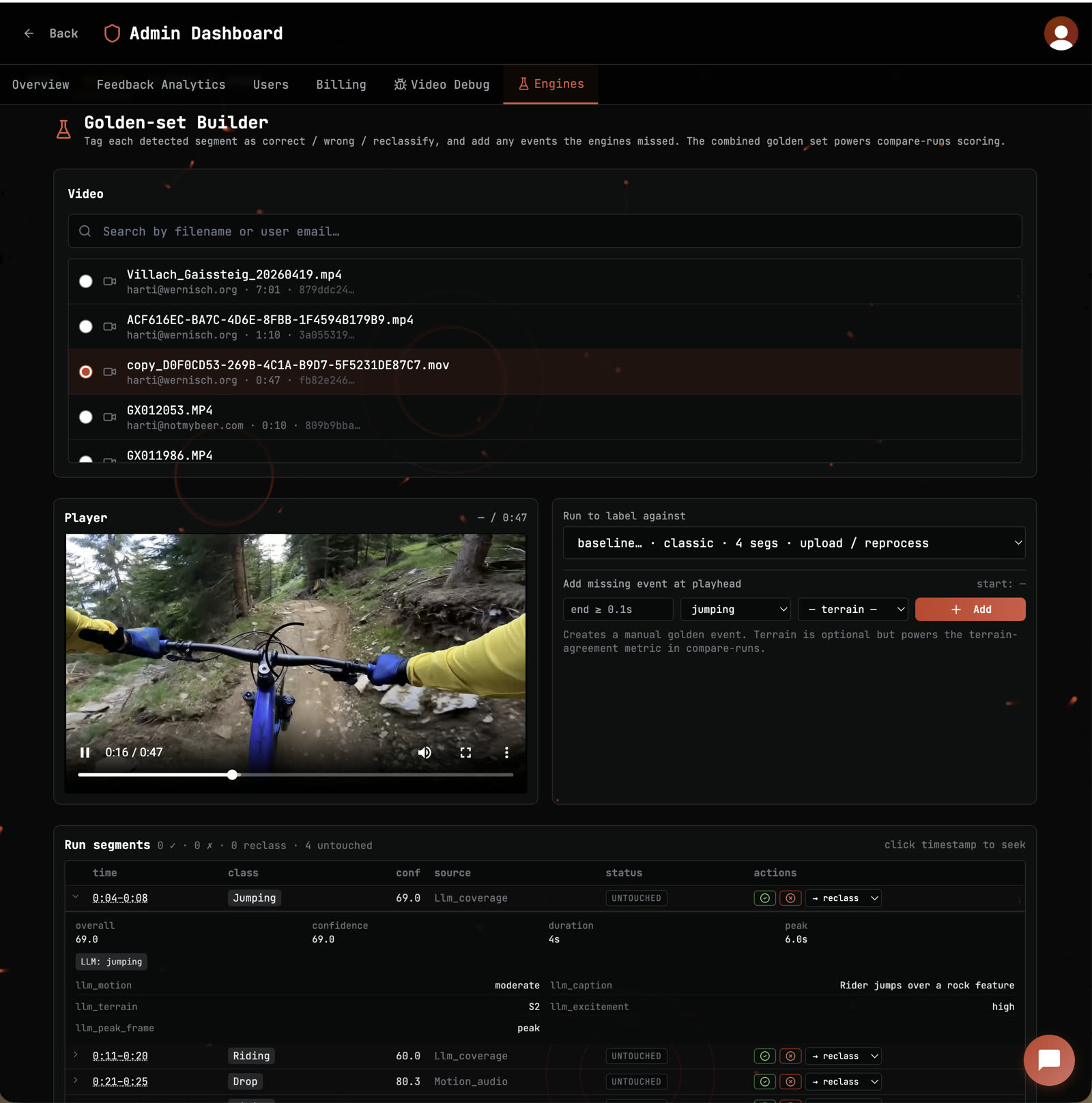
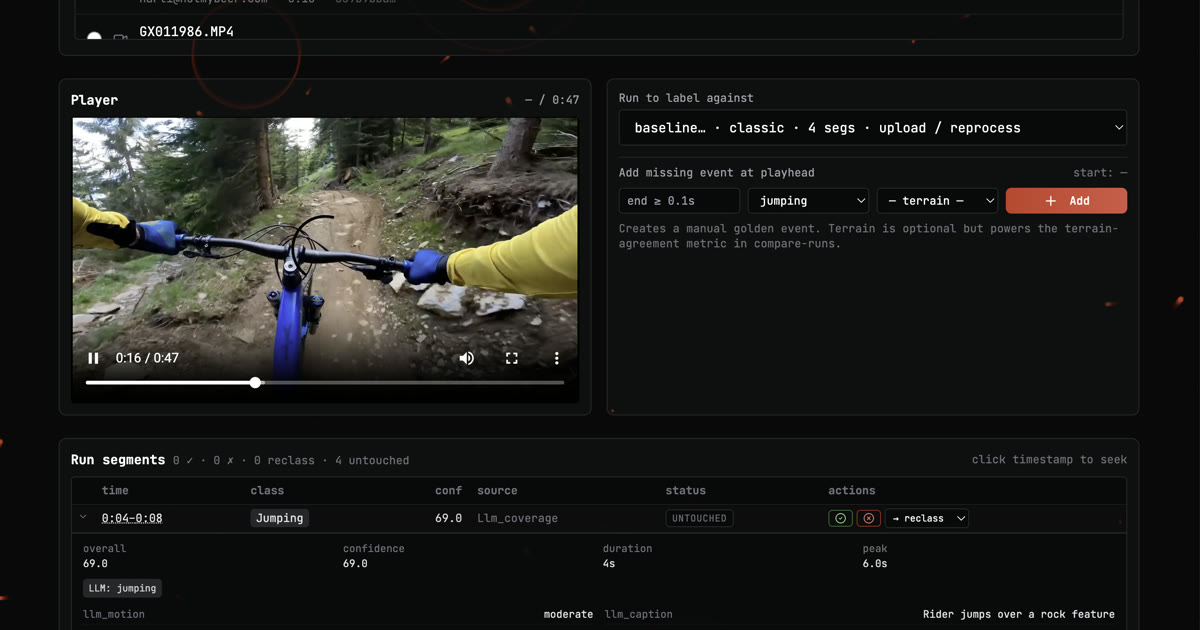
Das Dashboard zeigt mir jedes vom System erkannte Segment mit Confidence, Motion, Terrain und Caption. Ich tagge jede Detection als korrekt, falsch oder zu reklassifizieren. Verpasste Events ergänze ich manuell am Playhead. Daraus entsteht ein Ground-Truth-Datensatz aus echten MTB-Videos, die tatsächlich von Usern hochgeladen wurden.
Was gemessen wird
Jeder Engine-Release wird gegen den Golden Set laufen gelassen. Vier Metriken:
- Precision pro Action-Typ (Jump, Drop, Riding, Trick): Wie viele der erkannten Jumps waren wirklich Jumps?
- Recall: Wie viele der echten Events hat die Engine erkannt, wie viele verpasst?
- Terrain-Agreement: Stimmt die Terrain-Klassifikation (S1, S2, S3) mit der Ground Truth überein?
- Compare-Runs: Zwei Modell-Versionen auf demselben Set, direkt nebeneinander.
Beispiel aus der aktuellen Iteration: Baseline-Run erkennt vier Segmente in einem 47 Sekunden Villach-Clip. Jump 0:04-0:08 mit 69 Confidence, Caption “Rider jumps over a rock feature”, Terrain S2. Ich prüfe am Player, bestätige oder reklassifiziere. Das Ergebnis landet im Golden Set.
Wenn ich im nächsten Schritt einen Detection-Brick austausche oder Parameter ändere, sagt mir der Golden Set, ob der neue Stack auf denselben Videos besser performt, oder nur anders.
Kein Bauchgefühl mehr. Nur Messwerte.
Gilt auch bei Text-KI
Das Prinzip ist nicht auf Video beschränkt. Wer einen Chatbot betreibt, einen Telefonassistenten oder eine RAG-Lösung, steht vor derselben Frage: Ändere ich einen Prompt oder tausche das Modell, wird die Antwortqualität besser oder nur anders?
Die Antwort läuft gleich: Du brauchst einen fixen Satz an typischen Anfragen mit den erwarteten Antworten oder Quellen, und du misst jede Änderung dagegen. Bei Chatbots kommen noch Traces dazu, also die einzelnen Zwischenschritte eines Gesprächs, die du nachvollziehen können musst um zu verstehen wo Qualität verloren geht.
Dazu folgt ein eigener Artikel am Beispiel von ServasBot.at und LangSmith.
Was du davon mitnehmen kannst
Wenn du mit KI produktiv arbeitest oder planst, sie produktiv einzusetzen, stell dir früh die Frage: Wie weiß ich, ob es besser wird?
Ein Golden Set muss nicht perfekt sein. 20 typische Fälle mit bekannter richtiger Antwort sind besser als keine. Der Aufwand dafür zahlt sich beim ersten Modell-Upgrade oder Prompt-Refactor zurück, weil du dann nicht raten musst ob der Schritt nach vorne geht.
Wenn du gerade eine KI-Lösung baust oder tunst und dir unsicher bist wie du Qualität messbar machst, sprich mich an.